JDBC Connector
The JDBC connector is the DirX Identity connector that handles the import and export of information into and out of relational databases. It is based on the DirX Identity Connector Integration Framework. The connector implements the DxmConnectorExtended interface of the Java Connector Integration Framework.
Overview
The connector implements the API methods "add(…)", "modify(…)", "delete(…)", "search(…)" and "extendedRequest(…)". They represent the corresponding JDBC SQL statements INSERT, UPDATE, DELETE, SELECT and CALL stored Procedure.
Prerequisites
The JDBC connector is contained in
dxmJDBCConnector.jar.
The connector is based on the Java Connector Integration Framework. The framework is contained in the library
dxmConnector.jar.
Depending on the JDBC driver used, the appropriate jar file for the driver is also a prerequisite. For use in a Tcl workflow or standalone, follow the instructions given by the provider of the driver. If you use the driver in the Java-based Server (IdS-J), you need to put the jar file in the server’s install_path\ids-j-domain-Sn*confdb\common\lib* directory.
Configuration
The agent is composed of multiple sub-units (connectors), each configured within the configuration file. Here is the top-most level structure:
<?xml version="1.0" encoding="UTF-8" ?>
<job>
<connector
className="siemens.dxm.connector.framework.DefaultControllerStandalone"
name="Default Controller" role="controller" version="0.1">
</connector>
<connector name="JDBC connector" role="connector"
className="siemens.dxm.connector.jdbc.JDBCConnector">
<!-- additional JDBC connector material -->
</connector>
<connector className="siemens.dxm.connector.framework.SpmlFileReader"
name="SPML file reader" role="reader">
<connection filename="examples\\TestReq.xml" type="SPML" />
</connector>
<connector className="siemens.dxm.connector.framework.SpmlFileWriter"
name="SPML File writer" role="responseWriter">
<connection filename="examples\\TestRsp.xml" type="SPML" />
</connector>
</job>
This top-level structure conforms to the generic structure of the DirX Identity Agent Integration Framework, as shown in the following figure:
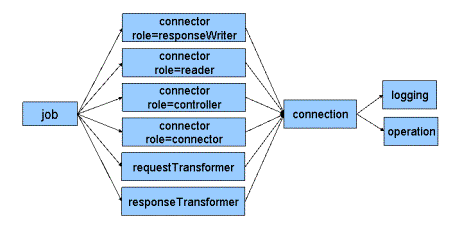
The readers and writers can also be configured to receive and accept LDIF.
Here, the only variable material (assuming the readers /writers specified here) is:
-
The line marked <!-- additional JDBCConnector material -→, which is described in the next sections.
-
The connector sections for the roles “reader” and “responseWriter”. They contain the input and output filenames (in bold) and the classes for the reader / writer. Use
“siemens.dxm.connector.framework. LdifChangeReader”
for LDIF change input format and
“siemens.dxm.connector.framework. LdifFileWriter”
for LDIF content output.
General Notes
This section provides general information about JDBC connector configuration.
JDBC Connector Element Form of the Connector
Here is an example of the contents of the two elements that form the sub-elements of the connector element, for the connector role within a JDBC connector. It is followed by a brief summary of key components. Further details and explanations are given later.
This is an example of the XML used in:
<!-- additional JDBCConnector material -→
as indicated above.
1:<connection
type="com.microsoft.jdbc.sqlserver.SQLServerDriver"
url="jdbc:microsoft:sqlserver://TIGGER2:1433;databasename=NorthWind"
user="sa"
...
driverDBType="siemens.dxm.connector.jdbc.SQLServerOverMicrosoftDriver"
driver_{property1}="value1"
driver_{property2}="value2"
...
driver_{propertyN}="valueN"
>
2: <jdbc-connection always-follow-references="false">
3: <tables-and-views>
4: <table>
5: <name>employees</name>
6: </table>
7: <!-- more tables -->
8: <view>
9: <name>employees</name>
10: <from>employees INNER JOIN Employees AS employeesAsBoss ON
employees.ReportsTo = employeesAsBoss.EmployeeID</from>
11: <where>employees.ReportsTo = employeesAsBoss.EmployeeID</where>
12: <table description="Employees">
13: <name>employees</name>
14: </table>
15: <table>
16: <name>employeesAsBoss</name>
17: </table>
18: </view>
19: </tables-and-views>
20: <abbreviation name="order-id">orders.OrderId</abbreviation>
21: <abbreviation name="boss">employeesAsBoss.FirstName + ' ' +
employeesAsBoss.LastName AS Boss</abbreviation>
22: <!-- more abbreviations -->
23: <relationship from="bossid" referring-to="id" />
24: <!-- more relationships -->
25: <functions-and-procedures>
26: <function name="ADD_FUNC">
27: <return>
28: <range exact="0" />
29: <range min="1" max="6" /> ]
30: <!-- more ranges -->
31: </return>
32: <argument name="base" in-out="in" preset="2" dataType="INTEGER" />
33: <!-- more arguments -->
34: </function>
35: <!-- more functions -->
36: <procedure name="add_proc">
37: <return name="result">
38: <range exact="0" />
39: <range min="1" max="6" /> ]
40: <!-- more ranges -->
41: </return>
42: <argument name="base" in-out="in" preset="2" dataType="DECIMAL" />
43: <argument name="addend" in-out="in" preset="5" dataType="INTEGER" />
44: <argument name="result" in-out="out" dataType="INTEGER" />
45: <!-- more arguments -->
46: </procedure>
47: <!-- more procedures -->
48: </functions-and-procedures>
49: </jdbc-connection>
50:</connection>
51:<logging filename="trace" level="5" logger="JDBCLogger"/>
Line 1 - specifies the details of the connection to the database. The attributes starting with the prefix driver_ are passed directly to the JDBC driver. This action allows additional configuration of user properties of the driver within the connector configuration. For example, a connection attribute driver_selectTimeout="10" would be passed to the driver as a user property selectTimeout with the value 10. Check the supported properties of the particular JDBC drivers and see the Java JDBC API for details.
Line 2 - jdbc-connection element - specifies general properties of the JDBC functionality
Line 3 - groups tables and views
Line 8 - table definitions,
Line 8 - view definitions, including table components
Line 20 - abbreviations - normally short-form names for DSML-stype attributes.
Line 23 - referential integrity definitions (called relationships)
Line 25 - groups function-and-procedure definitions
Line 26 - defines all stored functions
Line 36 - defines all stored procedures
Line 51 - <logging> - specifies JDBC connector-specific logging
Description Attributes
In the interests of legibility, description attributes have been omitted from the example. They are permitted as attributes of elements with the following tags:
-
tables-and-views
-
table
-
view
-
abbreviation
-
functions-and-procedures
-
function
-
procedure
-
FPReturn
-
range
-
argument
For descriptions of these elements, see the next sections.
Connector Element
The connector element with the attribute values name="JDBC connector" role="connector" is concerned with the detailed configuration of the JDBC connector.
The following sections describe the part of the XML that goes into the line marked <!-- additional JDBCConnector material -→ above. Two tags, connection and logging, are relevant.
connection
Defines the basic connection of the database and the means needed to support it.
logging
Defines the logging that will be available for the connection and its operation.
Connection Element
This section describes the attributes and sub-elements of the JDBC connector connection element.
Attributes
Configure the following required attributes:
- type
-
The class of the JDBC driver that you are using to access a database (normally a relational database).
Currently, the following are available:
-
For Microsoft SQL-Server 2000: com.microsoft.jdbc.sqlserver.SQLServerDriver
-
For Microsoft SQL-Server 2005 and newer: com.microsoft.jdbc.sqlserver.SQLServerDriver
-
For MS-Access (JDBC-ODBC Bridge): sun.jdbc.odbc.JdbcOdbcDriver
-
For MS-Access: net.ucanaccess.jdbc.UcanaccessDriver
-
For Oracle JDBC versions lower than 9.0.1: odbc.jdbc.driver.OracleDriver
-
For Oracle JDBC version 9.0.1 and higher: odbc.jdbc.OracleDriver
-
For PostgreSQL 9: org.postgresql.Driver
-
- url
-
The URL of the specific database to be accessed. The form of the URL will be described in the documentation for the JDBC driver.
- user
-
The name of the JDBC user: this user must be empowered to access the data (read and write) within the limits of planned use for the JDBC connector.
- password
-
The user’s password. May be omitted if it is just "".
- driverDBType
-
The Java class representing data-type capabilities and conversions for the combination of the selected database and the JDBC driver. If not supplied, a default capability is provided that should handle common eventualities.
Currently, the following are available:
-
siemens.dxm.connector.jdbc.AccessOverJdbcOdbcDriver representing sun.jdbc.odbc.JdbcOdbcDriver accessing Microsoft Access databases
-
siemens.dxm.connector.jdbc.SQLServerOverMicrosoftDriver representing com.microsoft.jdbc.sqlserver.SQLServerDriver accessing Microsoft SQL Server databases
-
siemens.dxm.connector.jdbc.OracleOverOracleDriver representing ORACLE drivers
-
siemens.dxm.connector.jdbc.DB2OverIBMDriver representing IBM DB2 drivers
-
siemens.dxm.connector.jdbc.PostgreSQLOverJdbcOdbcDriver representing PostgreSQL
-
Sub-elements
The following are the sub-elements of connection:
- jdbc-connection
-
Configures the connection to the database.
- Property debugfile
-
Set this property to enable the DriverManager logging. Logging goes to the specified prefix followed by some suffixes.
Example:
<property name="debugfile" value="JDBCTrace." />will result in a log file named like:
JDBCTrace._71_Wed_Oct_22_17.36.42_CEST_2008.log
- Property noSPcheck
-
Set this property to avoid check calls for configured Stored Procedures (SPs) during open. If you don’t specify this property or set it to false during open, every configured Stored Procedure is called with default values to check the configuration .(does the SP exist? Have you configured the right arguments? and so on.). Use this property to avoid these calls after successfully testing the Stored Procedure configuration.
Example:
<property name="noSPcheck" value="true" />
JDBC-Connection Element
This section describes the attributes and sub-elements for the JDBC-Connection element.
Attributes
The JDBC-Connection element has the following attribute:
- always-follow-references
-
Set this to "true" if it is required that the references supplied by relationship elements be followed and the pointing column value be set to null. Doing this may be a good idea to prevent pointers pointing "into thin air" when a pointed-to row is removed. It will not be necessary when all relationships are policed for relational integrity: in that case, the failure to carry out a delete operation triggers the following of references, and trying again to do the original deletion.
Sub-elements
The JDBC-Connection element has the following sub-elements:
- tables-and-views
-
Provides a general container for table and view specifications.
- abbreviation (multiple instances)
-
At least one of these must be present.
Provides a means to label columns of a particular table. Abbreviations can also represent expressions, such as can be used in an SQL SELECT statement:
SELECT RTRIM(x) AS xWithoutTrailingBlanks FROM …
However, such expressions cannot in general be used for adds (INSERTs) or modifies (UPDATEs).
See the section "Abbreviation" for details.
- relationship (zero or more instances)
-
A relationship specifies an abbreviation that corresponds to a column in some table that used to point to a row in a table; the two tables can be the same, but usually they are different. The pointed-to table must have a single primary key that is configured as an abbreviation.
- functions-and-procedures (optional)
-
Provides a general container for function and procedure specifications.
Logging Element
This element is optional. If absent, the controller log is used, with the level of logging set for it. The JDBC connector log has a default trace level of 3.
This element can contain just a level, which controls the catching of data as described in the following section. Whatever level of information is captured, the data is presented to the controller log, and is then passed to the user depending on the level of setting.
Attributes
The logging element has the following attributes:
- level
-
Controls the detail that is provided in trace-files. The following values apply:
3 → operation are reported, tagged with the request-id;
5 → Operation SQL is logged (i.e. SQL generated as a direct consequence of a user-requested operation);
7 → Causes calls to main functions in JDBC to be logged.
8 → Causes schema SQL to be logged (i.e. SQL generated as a result of JDBC functions to investigate schema matters);
9 → Causes table/column details to be logged.
For all information to be made available in the system log, the value of 9 or higher must be set for it. - logger
-
Provides a root filename for the log-file. If this is XXX, a typical output log-file is XXX.000.log.
Schema Names
At a more detailed level, several definitions require specification of schema objects, such as tables and columns. For this reason, the nature of names for these objects needs to be introduced. Such names are called "schema names".
There are two forms of names usable within the connector:
-
Unquoted names, which are case-insensitive, start with an alphabetic character and can contain alphanumerics or underscores '_' after the first character.
-
Double-quoted name, which are case-sensitive, cannot contain double quotes but are otherwise unrestricted.
| Not all databases use double quotes for the construction of generalized names: the JDBC connector identifies the native form for its own purposes. |
| In some elements where the SQL for access to a database is exposed (for example, in the construction of views), the SQL must comply with the standards for the database and double quotes may not be appropriate. |
The following is a synopsis of the rules:
Schema-names must be from 1 to 30 bytes long. They can be in one of two forms:
-
Unquoted
-
Double-quoted
Unquoted names are case-insensitive. They must begin with an alphabetic character (A-Z, a-z, no more) followed by one or more of:
-
Alphanumeric (A-Z, a-z, 0-9, no more)
-
underscore (_)
| Spaces and hyphens are not permitted. |
Double-quoted names are always enclosed in double quotation marks “…”. Such names can contain any combination of characters, including spaces.
In referring to a double-quoted name, you must always use double quotation marks whenever referring to the object. Enclosing a name in double quotes enables it to:
-
Contain spaces
-
Be case sensitive
-
Begin with a character other than an alphabetic character, such as a numeric character
-
Contain characters other than alphanumeric characters and _, $, and #
-
Be a reserved word
An uppercase unquoted name is taken as identical to the same name with double quotes
Table-and-Views Element
This section describes the attributes and sub-elements for the table-and-views element.
Sub-elements
The table-and-views element has the following sub-elements:
- table (1 or more instances)
-
The database table(s) to which the JDBC connector requires direct access. The first table specified is taken as the default table, and will be used when no other table can be deduced as relevant. Note that using an abbreviation does imply an associated table, except when the abbreviation specifies an expression that uses column values from more than one table.
- view (0 or more instances)
-
A view represents a join of tables. It is like a table in most respects, but it is unavailable for adds, modifies or deletes. In some regimes, a view can be specified directly in the view definition; in others (for example, Oracle9i), a view must be pre-configured into the database.
Table Element
A table always relates to a specific table in the underlying relational database.
Normally, a table has a defined column that supplies a primary key (usually auto-incrementing, for example, a steadily increasing row-id, but sometimes user-defined); sometimes multiple keys are used (for example, surname and given-name). This configuration provides a unique internal reference (the database may be able to police uniqueness of user-supplied keys). A user of the agent can still specify primary keys independent of the table configuration, provided that this is indeed guaranteed to provide a unique reference. If it does not, the specific rows in the sets that share a key cannot be modified individually using this key or set of keys.
| Abbreviations recorded in "keys" (and primary-keys) are not alternatives, but must normally be used together. In other words, if the abbreviations are "cn" and "gn", then both values should be supplied: cn=fred+gn=jones. Rows can sometimes be accessed by means of a subset of the keys, but sometimes they cannot (depending on whether the result is unique). |
For external purposes, specifying a different key is sometimes useful. For example, an entry from an LDAP directory system may be required to have a name corresponding to surname/given-name, while the primary key may be a number that is meaningless outside the database. For this reason, two forms of key are configurable - one for use with the database, and one for external use.
In some systems, the identity of the primary key can be obtained by the JDBC connector by accessing the table metadata. However, this is not always provided as a facility within the JDBC access to the database. If not available from configuration information, the agent assumes that the auto-incrementing columns of the table are the primary keys. If this is not possible, there is an error.
Attributes
The configured element has the following attributes:
- keys
-
An optional space-delimited list of abbreviations to be used as names useful to external resources. If absent, configured or evaluated primary keys are used.
- primary-keys
-
An optional space-limited list of abbreviations that correspond to primary keys as defined within the database. This is not required if (A) the Agent can obtain the information from schema metadata or (B) the table’s primary key(s) is/are auto-incrementing, and schema metadata can identify auto-incrementing columns.
The Agent will report an error if it is unable to determine a primary key.
View Element
A view represents a join of two or more tables. Joins can only be accessed by the JDBC connector for search operations. The first table within a view is referred to as the primary table.
In some environments (for example, Oracle9i), a view is a database object that is configured in by the database manager. In this case, "from" and "where" information is unneeded and must not be provided. In others (for example, Microsoft ACCESS or SQL Server), the join is explicitly generated in the calling SQL statement. In this case, "from" and "where" information is needed in exactly the same form as required by a manually-generated SELECT for two or more joined tables.
Attributes
The view element has the following attributes in addition to an optional description attribute:
- keys
-
An optional space-limited list of abbreviations to be used as names. These must represent columns of the first constituent table. If absent, the primary key(s) of the first table listed are used. (This must exist - see notes on "keys" and "primary-keys" under table-elements.)
Sub-elements
The view element has the following sub-elements:
- name (always one)
-
This is pure text. It must be unique for all views, but can be shared with its primary table. It must comply with the rules for schema names. (See section "Schema Names" for details.)
- from
-
Gives the FROM text needed for explicit views, in SQL. Mandatory when views are explicit. Absent otherwise.
If present, it must be exactly as the database would use it in a SQL statement. Note particularly that conventions for schema names containing spaces or other characters not permitted in basic schema names may apply. In this case, use as would be required for normal SQL when accessing the database with a command-line tool.
- where
-
Gives the WHERE text needed for explicit views, in SQL. Mandatory when views are explicit. Absent otherwise.
If present, it must be exactly as the database would use it in an SQL statement.. Note particularly that conventions for schema names containing spaces or other characters not permitted in basic schema names may apply. In this case, use as would be required for the normal SQL that would be used when accessing the database with a command-line tool. For example, double quotes may need to be replaced by square brackets for Access databases.
- table
-
Required to record all the tables specified in the Join. The first table must be the primary table.
In the case where the join is a self-join, the second instance of table must have been declared with a new name in an AS substatement in the WHERE clause used to define the join; this table must also be declared here.
For example:
<from>employees INNER JOIN Employees AS employeesAsBoss ON employees.ReportsTo = employeesAsBoss.EmployeeID</from>
requires also:
<table> <name>employeesAsBoss</name></table>
This permits the table to be used in an abbreviation definition, even though not specified with the main collection of tables.
This table element must contain a subordinate name element, which is text only.
Abbreviation
An abbreviation binds a simple externally-accessible name to a column or function defining information from a table or view. Simple abbreviations correspond to a single column. Functional abbreviations represent an expression based zero or more columns, perhaps from multiple tables. Thus the standard LDAP attribute name "sn" (meaning surname) could be bound in an abbreviation to the column:
Employees.LastName
meaning the column LastName in the table Employees.
Column values are only accessible when specified by an abbreviation that has been configured in the configuration file.
Abbreviations are checked when the agent is started, and should normally resolve to a table/column combination (except when an expression is specified).
"Abbreviation" is a term that corresponds closely to a textual DSML attribute descriptor (or an LDAP attribute identifier). Note that the latter two can be used in dotted-integer OID notation (for example, "2.5.5.1"); however, this facility is not supported by the JDBC connector.
DSML specifies a syntax for names; the textual form (as opposed to dotted decimal form is used for abbreviations.
Thus, an abbreviation has a name that must start with an ordinary alphabetic; thereafter, each letter in the name must be:
-
An alphabetic
-
A numeric
-
A hyphen
Abbreviation names are case-insensitive.
An abbreviation is more restrictive than a DSML attribute descriptor in corresponds to a unique column or expression in a database. Thus, in the case given earlier, "sn" cannot be used to represent a LastName column in any other table than Employees. This specific nature is exploited in the agent in that, since the abbreviation definition often identifies the holding table, it is often not necessary to specify the required table explicitly.
The abbreviation maps to a value defined by the text content of the element, initial and trailing spaces being discarded. This value could be:
-
A column name (when the table-name is unambiguous, because only one table has been declared)
-
A table and column name;
-
An SQL value expression identified as a quasi-column by an “… AS name” suffix.
<abbreviation name="exp">RTRIM(dbo.accounts.dxrAccountName) AS exp</abbreviation>
Defines that the RTRIM function is used to eliminate trailing blanks of the column dxrAccountName
Attributes
Abbreviation elements can have the following attributes in addition to an optional description attribute:
- format
-
This attribute is in a form that specifies the inner syntax of a string value (for example, for timestamps). Further details are given under section "Format Codes".
- max-size
-
An optional integer attribute that specifies the maximum size of a textual attribute value. The objective of this is to cause truncation when outgoing data is longer then the specified value. It applies only to string or text attributes.
- min-size
-
An optional integer attribute that specifies the minimum size of a textual attribute value. The objective of this is to cause an error when data intended for the database is shorter then the specified value. It applies only to string or text attributes.
- name
-
The name of the abbreviation. Mandatory, and must be unique for all abbreviations. It must comply with the rules for textual DSML Attribute Descriptors.
Abbreviations have pure text content. This text specifies the definition of the abbreviation in SQL terms. The recommended form for ordinary column-value abbreviations is:
-
<table-name>.<column-name>
where double quotes are used as necessary.
Format Codes
The format parameter is available to assist in the parsing of incoming values that are potentially cultural or locale dependent. At present, date-time is affected
Date-Time Formats
The abbreviation format field general date format which can then be used for parsing or string synthesis. Incoming dates are parsed in accordance with the format, and passed to the database (if appropriate) in a form compliant with JDBC standards. Similarly, outgoing dates are used to synthesize information in a defined manner.
Default format is "YYYYMMDDhhmmssZ". If running in lite mode only this format is supported.
| ACCESS over the ODBC/JDBC bridge does not apparently support date comparison in predicates. |
An example of the format string is:
-
"dd/MM of YYYY (hh:mm:ss GMT)"
In the string, the following are considered special:
-
"yy" or "YY" - indicates a two-digit year,
-
"yyyy" or "YYYY" - indicates a four-digit year,
-
"M" - indicates a one- or two-digit month,
-
"MM" - indicates a two-digit month,
-
"d" or "D" - indicates a one- or two-digit day,
-
"hh" or "HH" - indicates a two-digit hour,
-
"mm" - indicates a two-digit minute,
-
"ss" or "SS" - indicates a two-digit second,
-
"f", "ff" , … , "fffffffff" indicates fractions (number of decimal precision) of a TIMESTAMP
They mark the expected position of the indicated field. All other combinations are ignored. Care should be taken when additional characters contain any of the characters used in the special string. Thus, the word "Immediate" will not work as desired, since the two ms indicate an expected minute field. Year, month and day fields must be provided, and no field can be provided more than once. Fields can be adjacent, but if "D" "d" or "M" are immediately followed by another field, they are taken as the same as "DD", "dd" or "MM". Future extensions may give non-numerical (locale-dependent) dates.
For TIMESTAMP columns also fractions are allowed. Define the fractions in the format string of the abbreviation. Use f for fractions.
fff means 3 fractions (milliseconds format="YYYY-MM-DD hh:mm:ss.fff"). Up to 9 fractions are supported (9 decimal places of precision - nanoseconds).
The input data values must match the format string. Output data values are presented as defined in the format string.
You may use less fractions in format string as defined in the DDL of your column. During add / modify missing fractions are handled as 0.
If you have defined 6 fractions in your database column (microseconds), but you are using a format with fff (milliseconds), passing 123 as a fraction will be handled as 123000 microseconds.
Abbreviations and Data Types
Data types are at the heart of relational databases. Each database will define a range of data types that it is prepared to accept. To store any other kind of value, it would be necessary to map it into an existing data type (for example, a string), but, generally, the rule is that a column (represented by an abbreviation) has a predefined data type, and will only accept values of that data type (with minor variances, such as date-format). There could also be truncation (for example, of places in a floating-point format).
JDBC provides access to all normal data types (and to some unusual ones as well). However, the JDBC connector (while supporting the normal datatypes), does not support every JDBC-supported data type. The following list indicates the datatypes not supported.
-
Types.ARRAY
-
Types.BLOB *)
-
Types.CLOB
-
Types.DATALINK
-
Types.DISTINCT
-
Types.JAVA_OBJECT
-
Types.OTHER
-
Types.REF
-
Types.STRUCT
OracleOverOracleDriver supports BLOB in the following way:
BLOB input data must be of type binary.
BLOB data is returned as binary data. The length is limited to 2,147,483,647 bytes(MAXINT). BLOB data exceeding this size is ignored (no value for this column is returned). A warning is generated.
As BLOB data is handled as binary data it is transferred in SPML requests/responses as byte array. This may lead to high memory usage.
The following table indicates the standard data types and their standard mappings to Java classes:
| ARRAY | BIGINT | BINARY | BIT |
|---|---|---|---|
BLOB *) |
BOOLEAN |
CHAR |
CLOB |
DATALINK |
DATE - deprecated |
DECIMAL |
DISTINCT |
DOUBLE |
FLOAT |
INTEGER |
JAVA_OBJECT |
LONGVARBINARY |
LONGVARCHAR |
NUMERIC |
OTHER |
REAL |
REF |
SMALLINT |
STRUCT |
TIME - deprecated |
TIMESTAMP |
TINYINT |
VARBINARY |
VARCHAR |
NCHAR |
NULL |
NVARCHAR |
To determine whether a particular database requires a particular JDBC data type, an empirical approach usually suffices.
Each database defines its own data type names, but a table of mappings can sometimes be valuable. Here, for example, is a list of all the SQL Server data type names and the corresponding JDBC data type names. As you can see, all data types accessible to the server are supported:
| SQL Server Data Type Typename | JDBC Data Type Value |
|---|---|
bigint |
BIGINT |
binary |
BINARY |
bit |
BIT |
char |
CHAR |
datetime |
DATETIME |
decimal |
DECIMAL |
float |
FLOAT |
image |
LONGVARBINARY |
int |
INTEGER |
money |
DECIMAL |
nchar |
CHAR NCHAR (2008 and higher) |
numeric |
NUMERIC |
nvarchar |
VARCHAR NVARCHAR (2008 and higher) |
real |
REAL |
smalldatetime |
TIMESTAMP |
smallint |
SMALLINT |
smallmoney |
DECIMAL |
sql_variant |
VARCHAR |
text |
LONGVARCHAR |
timestamp |
BINARY |
tinyint |
TINYINT |
unique-identifier |
CHAR |
varbinary |
VARBINARY |
varchar |
VARCHAR |
Relationship Element
A relationship element specifies references from one table to another for which referential integrity enforcement (if implemented) can be handled by nullifying the reference. Use this element field to permit entries to be deleted when entries in other tables affected by referential integrity point to them. It is used in conjunction with the "always-follow-references" flag in the JDBC-Conection element (see section "JDBC-Connection Element"), each time a relevant row is deleted, the Agent attempts to null all configured pointers that would otherwise no longer point to a row.
In order for the JDBC connector to make use of this function:
-
The reference that points to the entry to be removed must be nullifiable
-
The access control that permits the JDBC connector to nullify the reference must be in force.
Attributes
The relationship element has the following attributes:
- from
-
An abbreviation that specifies the column in the table that contains a reference; this is the table that is affected by referential integrity. It is never a primary key
- referring-to
-
An abbreviation that specifies the column in the table that supplies the value of the reference. It is always a primary key - in fact, it must correspond to the single primary key for the referenced table.
Functions-and-Procedures Element
Functions and procedures are similar, except that a function returns a value and a procedure does not. Both functions and procedures theoretically have arguments that are IN, OUT, or IN-OUT. However, some regimes may be more restrictive (e.g. to forbid function arguments to be OUT or IN-OUT).
Functions and procedures have distinct names, so that a function and a procedure cannot share a name.
Sub-elements
A functions-and-procedures element has the following sub-elements:
- function
-
An optional declaration of a stored procedure that returns a value;
- procedure
-
An optional declaration of a stored procedure that does not return a value;
Returned Values
The JDBC connector requires that the function or procedure must return an integer result, representing status. This status is then converted in a customized way into either an indication of success, or an indication of failure.
Although this seems restrictive, functions and procedures can be nested inside each other, so that an arbitrary function or procedure (or a whole set of functions/procedures) can be encapsulated in a function or procedure that has the required characteristic.
Stored procedures cannot at present be actually created by the JDBC connector. They must be defined within the database by an appropriate graphic or command-line tool.
Function Element
This section describes the attributes and sub-elements of the function element.
Procedure Element
This section describes the attributes and sub-elements of the procedure element.
Argument Element
This section describes the attributes of the argument element.
Attributes
The argument element for the JDBC connector has the following attributes, as well as an optional description:
- in-out
-
Text of form "IN" "OUT" or "IN-OUT". Default: IN, if not specified.
- data-type
-
Defines the way in which the argument is to be interpreted.
- format
-
This attribute is in a form that specifies the inner syntax of a string value (for example, for timestamps). (See "Format Codes" in "Abbreviation" for details.) This is mandatory for all time-related data types like TIMESTAMP.
Return Element
Functions and procedures that are used by the JDBC connector must return an integer value that indicates success, failure, or other outcome. The return elements enable this value to be translated into:
-
The category of error
-
Text corresponding to the detailed value.
Attributes
The return element can have the following attribute:
- name
-
For a procedure, this must be the configured name of an argument. It is always absent for functions.
Sub-elements
A return element contains the following sub-elements:
- range
-
These sub-elements are used to map the returned integer value into a category and a report string.
The returned value is matched against each range in order of configuration, and the indications provided by the range are taken as the basis for the response made by the JDBC connector.
There is an error response if no range matches.
Range Element
This section describes the attributes of the range element.
Attributes
The applicability of a specific range to an integer return is determined by:
- max + min
-
These occur in pairs; if present, the integer return is matched if not exceeding max and not less than min.
- exact
-
Present if and only if max and min are absent. If present, the integer return is matched if equal to this value.
The translation of a return value is made in terms of the following attributes:
- value
-
The optional string return for a value within the specified range (default "")
- category
-
The severity of the return: If present, this must take one of the following values (ignoring case):
-
"OK"
-
"INFO
-
"WARNING
-
"ERROR
The default is "ERROR" if a value attribute is present, otherwise "OK".
-
Input and Output Data File Formats
The JDBC connector accepts different file formats for input data:
-
SPML request
-
LDIF change
Similarly, the agent produces the following different output formats:
-
SPML response
-
LDIF content
The format must be configured in the connector sections, which refer to the reader and the responseWriter.
The following sample configuration snippet defines LDIF-change input and SPML response output:
<connector className="siemens.dxm.connector.framework.LdifChangeReader"
name="LDIF change file reader" role="reader">
<connection filename="datain.ldif" type="LDIF change" />
</connector>
<connector className="siemens.dxm.connector.framework.SpmlFileWriter"
name="SPML File writer" role="responseWriter">
<connection filename="dataout.xml" type="SPML" />
</connector>
For an export, the agent waits for the search request definition in an SPML file. Here is a sample:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Created on Tue Jul 06 10:35:10 BST 2004-->
<searchRequest requestID="search8" xmlns="urn:oasis:names:tc:SPML:1:0">
<searchBase type="urn:oasis:names:tc:SPML:1:0#DN">
<spml:id>table=employees</spml:id>
</searchBase>
<filter>
<greaterOrEqual name="bd">
<value>1/1/1963</value>
</greaterOrEqual>
</filter>
<attributes>
<attribute name="sn"/>
<attribute name="bd"/>
/attributes>
</searchRequest>
The search results are output in LDIF content format. Here is a sample for the appropriate connector section in the configuration file:
<connector className="siemens.dxm.connector.framework.LdifFileWriter"
name="LDIF File writer" role="responseWriter">
<connection filename="dataout.ldif" type="LDIF" />
</connector>
Even if the input or output is of LDIF format, the agent internally works with SPML. Transformation is done automatically by the LDIF reader and writer.
The following subsections describe the content of the internally-handled input requests and output responses, which are in strict compliance with SPML requirements. You also need to know this format if you include transformation in your job: use a requestTransformer or responseTransformer section in your configuration.
The four main SPML operations are add, modify, delete, and select. The action is based on the supply of an identification, with the exception of add, which can optionally create a new entry based on new contents.
In addition, the extended-request SPML operation is used for function/procedure calls.
In all cases, the agent determines on which table to operate and then applies the supplied SPML information appropriately.
Add, Modify, Delete and Search Requests
The four defined operations add, modify, delete and search are extensions of SPMLRequest. Here are some simple examples. The first is for a database that maintains JDBC connector characteristics:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Created on Mon Jun 21 09:45:07 BST 2004-->
<addRequest requestID="add1" xmlns="urn:oasis:names:tc:SPML:1:0">
<attributes>
<attr name="abbname">
<value>boss</value>
</attr>
<attr name="abbmap">
<value>employeesAsBoss.FirstName & ' ' & employeesAsBoss.LastName AS Boss</value>
</attr>
<attr name="abbprice">
<value>1</value>
</attr>
<attr name="abbimp">
<value>false</value>
</attr>
</attributes>
</addRequest>
This is a modify for a personnel-style database:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Created on Mon Jun 21 09:45:11 BST 2004-->
<modifyRequest requestID="modify4" xmlns="urn:oasis:names:tc:SPML:1:0">
<identifier type="urn:oasis:names:tc:SPML:1:0#DN">
<spml:id>sn=davolio</spml:id>
</identifier>
<modifications>
<modification name="id" operation="delete"/>
</modifications>
</modifyRequest>
This relates to the same database as for the add:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Created on Mon Jun 21 09:45:09 BST 2004-->
<deleteRequest requestID="delete2" xmlns="urn:oasis:names:tc:SPML:1:0">
<identifier type="urn:oasis:names:tc:SPML:1:0#DN">
<spml:id>abbprice=2,table="abbreviation data and price"</spml:id>
</identifier>
</deleteRequest>
<?xml version="1.0" encoding="UTF-8"?>
<!-- Created on Mon Jun 21 09:45:13 BST 2004-->
<searchRequest requestID="search2" xmlns="urn:oasis:names:tc:SPML:1:0">
<searchBase type="urn:oasis:names:tc:SPML:1:0#DN">
<spml:id>table=employees</spml:id>
</searchBase>
<attributes>
<attribute name="id"/>
<attribute name="gn"/>
<attribute name="sn"/>
</attributes>
</searchRequest>
All operations have an optional reqestID. The reqestID is always repeated in any response.
Possible sub-elements for these operations are:
-
identifier (applicable to add, modify, delete only)
-
searchBase (applicable to search only)
-
modifications (applicable to modify only)
-
filter (applicable to search only) - specifies the search filter in SPML syntax. ApproximateMatch and ExtensibleMatch are not supported.
-
attributes - as types and values (applicable to add only)
-
attributes - as a list of types (applicable to search only)
-
operationalAttributes - sortAttribute, sortOrder and pageSize are supported for searches
-
any - unused
-
requested - unused
-
execution - unused
The usage of the protocol is as follows:
| add | modify | delete | search | |
|---|---|---|---|---|
identifier |
Optional. If present, points to the name of the new entry, supplying attribute values |
Mandatory. Defines the entry to be modified. |
Mandatory. Defines the entry to be deleted |
|
searchBase |
Optional. If present, defines what is to be searched. Defaults to definition by attribute selection |
|||
modifications |
Mandatory. Supplies modifications to be applied |
|||
filter |
Optional. Defines the entries of interest. |
|||
attributes (types and values) |
Optional. Supplies the main attributes to be added |
|||
attributes |
Optional. List of attribute descriptors that are to be returned - default all |
Sorting
Sorting can be specified with the operational attributes sortAttribute and sortOrder. If no sortOrder is given, ASCENDING is assumed. Multiple sortAttributes are supported.
In the following example, sorting is specified first ASCENDING for attribute JOB and second DESCENDING for attribute ENAME:
<spml:searchBase type="urn:oasis:names:tc:SPML:1:0#DN">
<spml:id>table=SCOTT.EMP</spml:id>
</spml:searchBase>
<spml:operationalAttributes>
<dsml:attr name="sortAttribute">
<value>JOB</value>
<value>ENAME</value>
</dsml:attr>
<dsml:attr name="sortOrder">
<value>ASCENDING</value>
<value>DESCENDING</value>
</dsml:attr>
</spml:operationalAttributes>
Paging
Paging can be configured with the operational attribute pageSize. The given pageSize is used for setting the "fetchSize" of the SelectStatement. If paging is configured, the SPML response does not include the whole result set to minimize memory consumption. For database-specific optimization, see the DB /JDBC documentation. (For example, SQL Servers offers responseBuffering=adaptive.)
In the following example, paging is specified with pagesize 5:
<spml:searchBase type="urn:oasis:names:tc:SPML:1:0#DN">
<spml:id>table=SCOTT.EMP</spml:id>
</spml:searchBase>
<spml:operationalAttributes>
<dsml:attr name="pageSize">
<value>5</value>
</dsml:attr>
</spml:operationalAttributes>
Names within Identifier and Search-base Elements
Names as used by the connector within identifier and search-base elements are always represented in XML as follows:
<identifier type="urn:oasis:names:tc:SPML:1:0#DN"> <spml:id>dn</spml:id> </identifier>
where dn represents the LDAP DN form specified in RFC2253. This is the only SPML-specified type that is supported.
The name used for a search operation is known as the "search-base", and can correspond to a table or to a specific entry (row).
Four DN forms are recognized by the connector:
| No. | Description | Signifying | Example(s) |
|---|---|---|---|
2 |
Empty string (the "root" name) |
Default table |
empty or blanks |
3 |
A name comprising a single RDN built out of keys (one or more attributes). |
A row matching these values |
sn=Doe,gn=John |
4 |
A name comprising a single DN built from the quasi-attributes: table and view |
A table matching the name (including double quotes) |
view=employees |
5 |
A two-RDN name combining keys with table or view. |
A row matching these values |
sn=Hodson,table=suppliers |
The quasi-attributes table and view are used with values that are exactly as required for the table or view. For these, values without double-quotes are case-insensitive and are very restricted in the characters that they can use, and values with double-quotes are taken as case-sensitive, and can include spaces and other characters.
These restrictions do not apply to other attributes.
The following table defines the use of the four forms described above by JDBC connector operations:
| add | delete | modify | search | |
|---|---|---|---|---|
1 - empty |
forbidden |
forbidden |
forbidden |
OK (default table implied) |
2 - keys |
OK |
OK |
OK |
OK |
3 - table or view |
table is OK |
Forbidden (this would drop a table or view, which is forbidden). |
Forbidden (you can only modify a row, not a table or view). |
OK |
4 - keys and table |
OK |
OK |
OK |
OK |
The name itself must be compatible with any other attributes defined within the specific operation (i.e. represent a table, view, row or join of rows), within which the required attributes can be found. The following additional rules exist for identification purposes:
| add | delete | modify | search | |
|---|---|---|---|---|
1 - empty |
||||
2 - atts |
Must not define any existing row |
Must define a single row |
Must define a single row |
May define one or more rows |
3 - table or view |
Must define a configured table |
Must define a configured table or view |
||
4 - atts and table |
Must not define any existing row |
Must define a single row |
Must define a single row |
May define one or more rows |
Add, Modify, Delete, and Search Responses
The following table defines responses with success:
| add | modify | delete | search | |
|---|---|---|---|---|
result: |
"urn:oasis:names:tc:SPML:1:0#success" |
|||
requestID |
returned if supplied |
|||
identifier |
Always returned based on primary key |
|||
attributes |
unused |
|||
modifications |
unused |
|||
searchResultEntry |
Returns names and values for matching entries |
|||
operational attributes |
unused |
|||
error Message |
||||
any |
unused |
The following table defines responses with failure:
| add | modify | delete | search | |
|---|---|---|---|---|
result: |
"urn:oasis:names:tc:SPML:1:0#failure" |
|||
requestID |
returned if supplied |
|||
error |
absent OR |
|||
operational attributes |
unused |
|||
error Message |
absent OR |
|||
any |
unused |
Examples:
<AddResponse result="urn:oasis:names:tc:SPML:1:0#success" requestID="add7" xmlns="urn:oasis:names:tc:SPML:1:0">
<identifier type="urn:oasis:names:tc:SPML:1:0#DN">
<id>
abbid=7,table=\"abbreviation data and price\"
</id>
</identifier>
</AddResponse>
<DeleteResponse result="urn:oasis:names:tc:SPML:1:0#success" requestID="delete1" xmlns="urn:oasis:names:tc:SPML:1:0"/>
<SearchResponse result="urn:oasis:names:tc:SPML:1:0#failure" requestID="search99" xmlns="urn:oasis:names:tc:SPML:1:0">
<errorMessage>
search error:entry not found; dn=sn=davo\+lio+gn=nancy\,
</errorMessage>
</SearchResponse>
Stored Functions and Procedures
This section describes the operations for stored functions and procedures.
extendedRequest Elements
Stored functions and procedures are mapped to extendedRequest SPML operations. The form of these items differs from the other operations described earlier in this document.
The components of an extendedRequest as used by a functions and procedures are illustrated in the following example:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Created on Mon Jun 21 09:45:15 BST 2004-->
<extendedRequest requestID="spin00_3" xmlns="urn:oasis:names:tc:SPML:1:0">
<providerIdentifier providerIDType="urn:oasis:names:tc:SPML:1:0#URN">
<providerID>SP</providerID>
</providerIdentifier>
<operationIdentifier operationIDType="urn:oasis:names:tc:SPML:1:0#GenericString">
<operationID>sp_benutzerrolle</operationID>
</operationIdentifier>
<attributes>
<attr name="operation">
<value>2</value>
</attr>
<attr name="rollenname">
<value>fred</value>
</attr>
<attr name="mitarbeiter">
<value>tom</value>
</attr>
</attributes>
</extendedRequest>
Items which are in bold represent user-supplied information:
-
text value of operationID as the name of the function
-
attributes elements
-
value of name attribute
-
text value of value sub-element
-
The attributes are used to map to the arguments of a pre-stored procedure definition. The names of the arguments are used in the same way that abbreviations are used for normal operations. Normal abbreviations are unused.
The return value can either be success or a failure with diagnostics, or could take a processed value; and the "attributes" element of the extendedResponse (part of the extension of the SPML response) could provide the other return values.
The process for stored functions and procedures is:
-
The values supplied as attributes are applied to the appropriate arguments, if present. If absent, NULL values are used.
-
On successful return of a function, the returned value is matched to a range provided by conversion. On successful return of a procedure with a defined return, the returned value is similarly handled.
-
If the return is empty, or is designated as OK, info, or warning, the extendedResponse indicates success.
-
Otherwise, the extendedResponse indicates failure
-
All values of OUT or IN/OUT arguments including the returned value are returned as attribute values.
The returned value for the function or procedure must always be an integer.
extendedResponse Element
An example of a successful response is:
<ExtendedResponse result="urn:oasis:names:tc:SPML:1:0#success" requestID="spin00_1" xmlns="urn:oasis:names:tc:SPML:1:0">
<attributes>
....<attr name="return-message">
......<ns1:value xmlns:ns1="urn:oasis:names:tc:DSML:2:0:core">
OK
......</ns1:value>
....</attr>
....<attr name="return-value">
......<ns2:value xmlns:ns2="urn:oasis:names:tc:DSML:2:0:core">
........11
......</ns2:value>
....</attr>
..</attributes>
</ExtendedResponse>
Elements of successful responses are given in the following table:
| Stored Functions and Procedures | ||
|---|---|---|
result: |
"urn:oasis:names:tc:SPML:1:0#success" |
|
requestID |
returned if supplied |
|
attributes |
Contains return values, encoded in terms of attribute names. There will always be at least one of these. For a function, the return value will have a name "function-return-value" |
|
"return-message" |
present if supplied as a result of range in one of the following forms: OK: message |
|
return-value |
always supplied - always an integer |
|
argument-names |
argument-values |
|
operational attributes |
unused |
|
error Message |
||
any |
unused |
Elements of failed responses are given in the following table:
| Stored Functions and Procedures | ||
|---|---|---|
result |
"urn:oasis:names:tc:SPML:1:0#failure" |
|
requestID |
returned if supplied |
|
error |
absent |
|
attributes |
Contains return values, encoded in terms of attribute names. Only supplied if the function or procedure successfully executed, but detected an error within its own processing. |
|
"return-message" |
present if supplied as a result of range in this form Error: message |
|
"return-value" |
always supplied - always an integer |
|
argument-names |
argument-values |
|
operational attributes |
unused |
|
error Message |
Present if no attributes are available. Synthesized using Reports substitutions |
|
any |
unused |
Error Handling
This section describes JDBC connector error handling, including:
-
Generated error log files
-
Error-handling procedures
Error Log Files (JDBC Connector)
Errors are logged in a system log file provided outside the scope of the JDBC connector.
Errors are also optionally logged in a local log file whose name is derived from the configuration file attribute:
-
job.connector.logging.filename
For example, with a value "JDBCLogger", the file name may be:
-
JDBCLogger.000.log
The level of logging is set by the levels set for each of the log files. But note that the information provided by the system log file is no more extensive than that made available by the level set for local logging (whether or not a local log file is provided).
Error-Handling Procedures
Configuration errors are normally fatal.
Operation errors usually cause the operation to fail, but do not stop the connector.
Failed operations cause an error response, which carries a single message representing a failure. Logged messages can contain indications of multiple error events.
The language of errors depends on resource files, which change the language of textual messages but do not affect tags that represent the name of XML elements.