Deprecated Features
This section contains features that still work but should not be used because better features are available.
Use the Java-based workflows instead of the Tcl-based workflows described in this chapter.
Note that the features described in this chapter are still supported but will not be enhanced.
ADS Provisioning Workflows
This section comprises all issues related to Active Directory and Exchange Provisioning workflows.
Exchange Server 2007 Provisioning Workflow
Microsoft strongly recommends that you install Exchange Server 2007 on a 64-bit processor machine with a 64-bit operating system, even though it is possible to install it on a 32-bit processor machine. Also at least one domain controller that is the schema master must have Windows Server 2003 Service Pack 1 installed.
For further hardware and software requirements as well as the required steps to prepare Active Directory, the domains and the forest for Exchange 2007, refer to the Microsoft documentation.
To administer Exchange Server 2007 including the administration of mailbox-enabled users (if the mailbox Server role was installed) you can install the Exchange 2007 management tools, which consist of the following:
-
Exchange Management Console
-
Exchange Management Shell
-
Exchange Help File
-
Exchange Best Practices Analyzer Tool
-
Exchange Troubleshooting Assistant Tool
Creating Mailbox-enabled Users:
To create mailbox-enabled users with the Tcl-based provisioning workflows (C++-based AdsAgent) the following changes in the attribute mappings must be done:
The attribute “textEncodedORAddress” can be eliminated from the mapping because Exchange 2007 does not support the X400 provider anymore by default.
The attribute displayName has to be set to make the created mailbox enabled user work properly together with the Exchange 2007 GUI. For example map the LDAP cn attribute to the Exchange displayName attribute.
In addition to the known attributes that must be set on creation of a mailbox-enabled user the following ones can be set:
-
msExchRecipientTypeDetails
-
msExchVersion
-
msExchRecipientDisplayType
Setting these attributes prevents the created mailbox to be shown as Legacy Mailbox by the Exchange Management Console tool. By Exchange 2007 a Legacy Mailbox is regarded as a one that resides on an Exchange 2000/2003 server or that has been created by an Active Directory Users and Computers snap in extended by Exchange 2000/2003 functionality.
To make a Legacy Mailbox a User Mailbox also the Exchange Management Shell command setMailbox with the ApplyMandatoryProperties parameter can be used:
C:\>Set-Mailbox -Identity USERNAME –ApplyMandatoryProperties
Configuring with C++ based AdsAgent:
In the import.ini file the attributes must be set with the following types:
-
msExchRecipientTypeDetails=Integer
-
msExchVersion=CaseIgnoreString
-
msExchRecipientDisplayType=Integer
Mapping with both C++-based and Java-based agent or connector:
Set these attributes in the mapping to constant values:
-
msExchVersion: 4535486012416 (optional)
-
msExchRecipientDisplayType: 1073741824 (optional)
-
msExchRecipientTypeDetails: 1 (mandatory)
Dashboard Workflow
The DirX Identity Dashboard workflow provisions a Dashboard target system. The following workflow is available:
-
Ident_Dashboard_Sync - exports data from the Identity Store and imports it to the Dashboard target system and vice versa
Note that the complexity of the Dashboard system requires a workflow of corresponding complexity to handle all of Dashboard’s features. The next sections provide conceptual and operational information about the Dashboard workflow.
Dashboard Workflow: General Issues
DirX Identity synchronization workflows read information from the Identity Store, perform the necessary update operations in the target system, read the target system content and update the Identity Store information accordingly. This procedure sets the status information in the identity store to correct and consistent values.
Because the Dashboard system handles a set of other target systems and is not readable through its interfaces, DirX Identity uses a special procedure to handle this target system. The following figure illustrates this procedure.
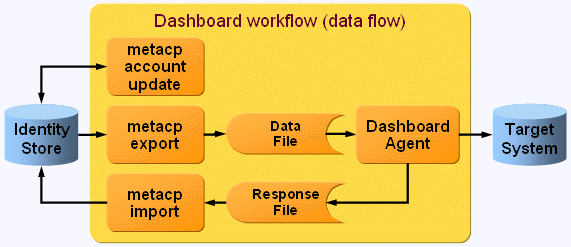
As illustrated in the figure:
-
The first activity - the meta controller (metacp) account update - collects the account information from all associated target systems and writes it at the corresponding Dashboard account.
-
The next activity operates like workflows for other target systems. The metacp export activity reads all necessary information from the Identity Store and writes it to the data file. The target system agent (the Dashboard agent) writes this information to the target system.
-
Depending on the result of the corresponding target system interface (API) action, the Dashboard agent writes a response file that contains the distinguished names (DNs) of all accounts where the operation was successful. Other results are only documented in the trace file.
-
An additional meta controller activity - metacp import - uses this response file to update the relevant status information in the Identity Store.
The entire procedure assumes that the target system interface (API) reports correctly whether an operation was successful or not. On success, the target system agent writes the corresponding entry into the response file.
Prerequisites and Limitations
Before you can use the Dashboard workflow, you must extend the DirX Identity Store schema with Dashboard target system-specific attributes and object classes so that the workflows can store Dashboard-specific information in the Identity Store. For instructions, see the section "Extending the Schema for the Target System Workflows".
Dashboard Workflow: Operational Features
In order to understand the Dashboard workflow, you need to understand the relevant features of the Dashboard system:
-
Each user must have a corresponding account in the Dashboard system. The account name is necessary to authenticate to the Dashboard system.
-
The Dashboard account has a category attribute that defines the authorization to the external applications that are configured in Dashboard. A category can enable access to one or more applications. It is not possible to refine the access to specific functionality within an application.
-
One physical target system can be represented by several applications within Dashboard that model a part of the available functionality.
-
Dashboard can handle single sign-on to the external applications. To provide this feature, Dashboard keeps, for each user, the relevant account information of the external applications (username and password). Three facets exist:
-
Common account: The external application uses the same username and password that Dashboard itself uses. In this case, the account information is set to "username=" and "password=".
-
Common password: The external application uses a different username but the same password that Dashboard uses. In this case, the account information is set to "username=TSusername" and "password=*".
-
Diverse account: The external application uses a username and password that are different from the ones that Dashboard uses. In this case, the account information is set to "username=TSusername" and "password=TSpassword".
In a DirX Identity Connectivity scenario, it only makes sense to support the first two facets. The third one is not supported.
-
The Dashboard system also supports several authentication types:
-
Simple type: The password is kept during the Dashboard session. If an external application entry of a Dashboard account contains an asterisk ('*'), the session password is used to log into the external application; otherwise, the stored value is used as the password for login.
-
Password-less type: Other authentication types, for example, reuse of the Windows login, cannot provide the password. Therefore the "asterisk" solution does not work. In this case, the password of the Dashboard account and all passwords of the external application entries must be set to the same value.
Dashboard’s category feature is a type of role model (with hierarchies and so on.). Users are assigned categories (for example, Physician or Nurse) to enable them to access several specific Web pages that may in turn be bound to external applications. Dashboard only handles the access to the application. It cannot handle fine granular access within the external applications.
The next figure shows the Dashboard privilege model and its relationship to external applications.
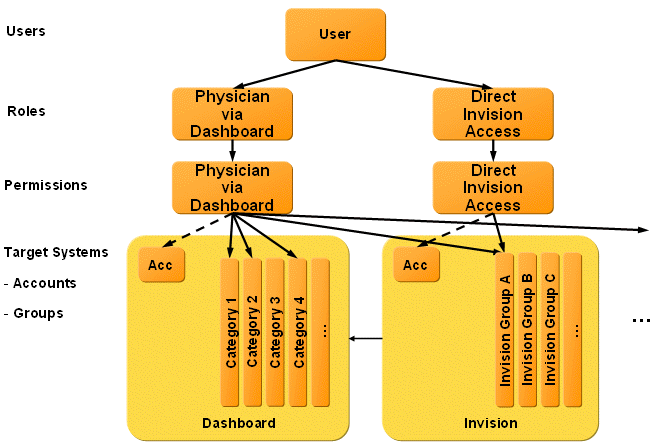
Assume a physician needs to work with the external applications Invision and Pharmacy. This access can be modeled as a Physician role that uses a Physician permission that has the following groups assigned to it:
-
One or more categories in the Dashboard target system to obtain basic access to the Dashboard system (to ensure Dashboard account creation and enabling).
-
One or more groups in the Invision target system for fine granular access to Invision. This assignment creates the necessary Invision account.
-
One or more groups in any additional target systems (for example, Pharmacy) for fine granular access to these additional systems. This assignment creates the necessary target system account.
-
The target systems must be marked as Dashboard-relevant systems (The Peer Target System property must point to a Dashboard target system within DirX IdentityTS).
With this approach, inconsistencies might occur. If a user gets an account in a target system that is not enabled (on the portal of the user) by one of the assigned Dashboard categories, the user cannot enter the application via Dashboard (but he can via the application’s native access). To ensure that the target system is accessible, you must create an "access category" for each target system that is assigned to the user via a permission if one of the groups of the target system is assigned. The advantage of this approach is that the whole access control model is visible within DirX Identity (that is, DirX Identity can ensure correct access to the target system).
To summarize the model within DirX Identity: DirX Identity contains a Dashboard target system with all necessary Dashboard accounts. The groups represent the Dashboard categories. A special attribute at the Dashboard target system object defines whether simple or password-less authentication is used.
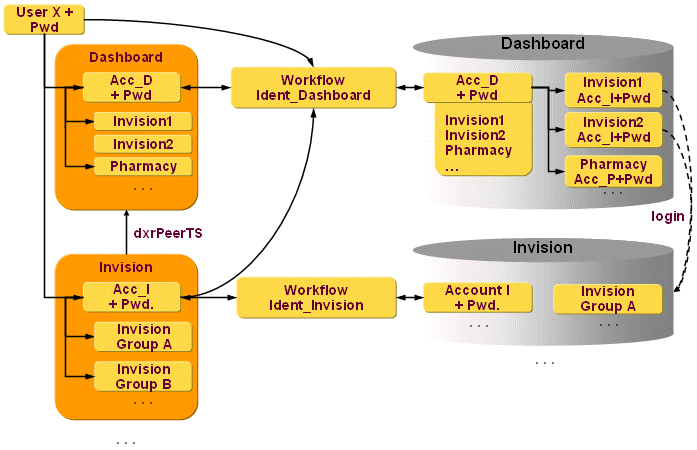
DirX Identity also contains a set of Dashboard-managed target systems. These target systems have their own accounts for these users and target system-specific groups and group memberships. Such a target system can be represented as several external applications in the Dashboard system (e.g., Invision can be represented as Invision1 as Invision2). Because the name of the target system might be different from the names of the external applications which are represented by this target system in Dashboard, you can set the external application names in the Portal External Application property of each of the associated target system. The user can log in to one of the available Invision applications (Invision1 or Invision2).
The workflow works as follows:
-
To get the active relevant accounts and its names (dxmDshExternalApp) for one of the Dashboard accounts, the first workflow activity retrieves all non-deleted accounts (active or inactive) for this user from all target systems that have the Dashboard target system set as Peer Target System property. If such a target system has set several names in the Portal External Application property, each name is used as a separate external application for the Dashboard account. The external application account name is then equal to the value of the dxrName attribute of the account in the external application (target system). If the dxrName attribute is empty the attribute cn is used instead. Just one account per target system is selected (the primary one in case of multiple accounts) and is configured for all the names listed in Portal External Application property. The inactive external applications are evaluated as a complement of the currently resolved list of external applications to the list of external applications in a previous run of the workflow and are written to the dxmDshExternalAppDel attribute.
Note that this activity needs to know the location of the Dashboard target system account base. This information is retrieved from the Identity Store’s account base attribute that is set automatically from the target system wizard. This concept restricts the number of Dashboard target systems per configured identity store to exactly one. -
The second activity reads the user’s Dashboard account and all necessary account attributes. Additionally it fetches the related user’s password from the identity store as initial password (specified by the dxrUserLink attribute of the account). This assures that the actual password is taken. If the dxrUserLink attribute of the account is missing or no password for the user exists, a default value is used (configured in the post join mapping script of the second job).
-
The assigned group memberships are transferred as categories to Dashboard.
-
The workflow adds external application attributes (retrieved from the dxmDshExternalApp and dxmDshExternalAppDel attributes) to each Dashboard account entry with account name and password information.
-
If the attribute Prevent Password Synchronization of a Dashboard relevant target system is set, the workflow sets empty passwords for all the related external applications accounts. Otherwise the workflow uses the star ('*') or the value of the user’s password (according to the simple or password-less authentication type setting of the Dashboard target system).
-
All the information is transferred via the Dashboard agent to the Dashboard target system.
-
Dashboard response is joined with the Dashboard user data stored in the identity store. The relevant target system state is set.
Dashboard Password Synchronization
The Dashboard password synchronization workflow that uses the Dashboard connector synchronizes the Dashboard password and all the Dashboard-related target systems that do not use empty passwords. The external applications for a Dashboard account are taken from the actual values of the attribute dxmDshExternalApp. The password for external applications is then set according to the authentication type of the Dashboard target system.
DirX Access Workflows
| These workflows are no longer usable. Read the information in the chapter DirX Access Workflows to understand how DirX Identity and DirX Access can interact. |
The DirX Access provisioning workflows work between a target system of type SPMLv1 in the Identity Store and the corresponding connected DirX Access server with configured Provisioning Web Service.
The workflows use the SPML connector (SpmlV1SoapConnector2TS) for provisioning. This connector communicates with the DirX Access Provisioning Web Service. The following figure illustrates the DirX Access provisioning workflow architecture.
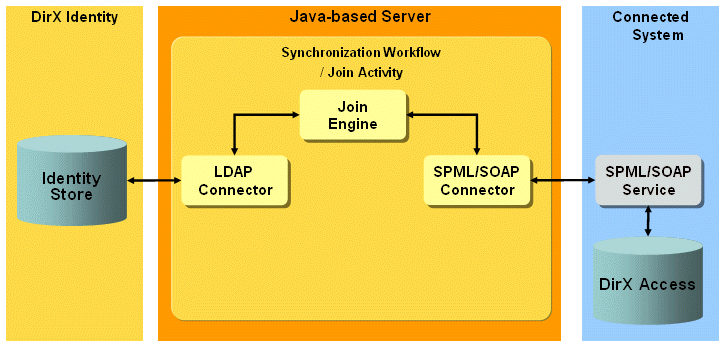
The workflows handle the following objects:
User - the common DirX Access user.
Role - the common DirX Access business role.
The delivered workflows are:
-
Ident_DXA_Realtime - the synchronization workflow exports detected changes for user (account) and business role (group) objects from Identity Store to the DirX Access server in the first step. The second step is to validate the processed changes in the DirX Access server to the Identity Store.
-
Validate_DXA_Realtime - the validation workflow imports existing DirX Access users and business roles with role assignment from the DirX Access server to the Identity Store.
DirX Access Prerequisites and Limitations
The DirX Access workflows support only DirX Access user and business role objects. They do not support password synchronization for DirX Access.
Configuring DirX Access Workflows
To configure the connection to DirX Access:
-
Specify the IP address and the Data Port of the DirX Access SPML v1 Provisioning Web Service. Use the corresponding DirX Access service object which is the part of the connected DirX Access system.
-
You can configure the URL Path and Socket Timeout at the target system port of the appropriate workflow object. (See the DirX Access provisioning workflows configuration in the Expert View in the Connectivity part in the DirX Manager.) You can change the URL Path according to real deployment of the DirX Access Provisioning Web Service. You can increase the timeout value (in seconds) in the Socket Timeout if necessary.
-
Set up the bind credentials of the connected DirX Access system. Use the correct credentials with sufficient rights.
-
Check the provisioning settings used by the connected DirX Access system. Specify them according to real values for your provisioned DirX Access target system.
Configuring the DirX Access Target System
The DirX Access target system requires the following layout:
-
Accounts - all DirX Access users are located in a subfolder Accounts.
-
Groups - all DirX Access business role objects are located in a subfolder Groups.
The attribute dxrPrimaryKey of accounts and groups contains the PSO Identifier of these objects in the connected DirX Access system. (See the SPMLv2 specification for more details about PSO Identifiers.)
The business role (group) membership is stored at the user (account) object and references the dxrPrimaryKey attribute of business role (group) objects.
DirX Access Workflows and Activities
The following figure shows the layout of the channels that are used by the UNIX-PAM workflow’s join activity:
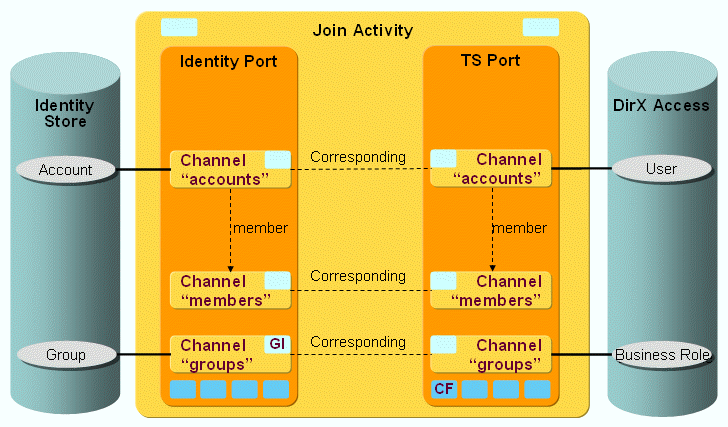
The DirX Access users (with membership) and business roles are synchronized via a pair of channels (one channel per direction).
DirX Access Ports
This section describes the DirX Access ports.
TS Port
-
CF - Crypt Filter
A DirX Access filter is configured implicitly. It is used to send the decrypted password attribute password to DirX Access.
DirX Access Channels
This section provides information about DirX Access channels.
Common Aspects
Direction: Identity Store → DirX Access
-
enabled - the attribute used for disabling of the user object in DirX Access. The correct value is derived from the dxrState attribute of the corresponding account object in the Identity Store.
Direction: DirX Access → Identity Store
-
CommonProcsDxa.calculateIdInIdentity - calculates the ID.
Accounts
Direction: Identity Store → DirX Access
-
ID: dxrPrimaryKey
-
Join: ${source.dxrPrimaryKey} or ${source.dxrName} identical to loginName
-
DirX Access requires some mandatory attributes. Mandatory attributes are mapped mostly in a common way, some are mapped as constants.
-
The roles attribute holds the business group membership.
Direction: DirX Access → Identity Store
-
Join via the dxrName attribute that is mapped identically to the loginName attribute.
Groups
Direction: Identity Store → DirX Access
-
ID: dxrPrimaryKey
-
Join: ${source.dxrPrimaryKey}
-
DirX Access requires some mandatory attributes. Mandatory attributes are mapped mostly in a common way, and some are mapped as constants.
-
The mode attribute must be set to 1 for business roles.
Direction: DirX Access → Identity Store
-
Join via the dxrName attribute that is mapped identically to the name attribute.
-
Post-mapping removes all administrative roles from the imported DirX Access roles (it simply omits the roles with the mode attribute set to 0).
JDBC Provisioning Workflows
The DirX Identity JDBC workflows provision a JDBC target system. The following workflows are available:
-
JDBC2Ident_Validation - performs initial loads or validations from the JDBC target system
-
Ident_JDBC_Sync - synchronizes between the JDBC target system within DirX Identity and the real JDBC target system.
The next sections provide information about JDBC workflow implementation.
General Information about the JDBC Workflows
Because the JDBC workflows assume the same database structure as the ODBC workflows, the workflow structure is also the same. They also use the ODBC Tcl scripts, especially the ODBC profile script.
Because JDBC workflows use the JDBC agent, joins are configured here in a special view section. The join feature is not needed in all JDBC jobs, but all jobs are configured the same way.
The JDBC agent is always run in full mode (a delta filter feature is not yet available). As a result, deleted records in the JDBC database are never exported. As a result, the TSState attribute in the identity store cannot be updated for deleted accounts or groups. Use the validation workflow to perform this task.
JDBC System Table Layout
The JDBC workflows assume the following table layout in the JDBC target system:
-
A table of groups, where each row represents one group
-
A table of accounts, where each row represents one account
-
A table of memberships, where each row represents a membership of one account in one group
JDBC Workflow Configuration
The JDBC agent’s import and export configuration files are stored under the JDBC connected directory. As in the attribute configuration, the database schema is described here. Each JDBC export job uses this configuration.
For searchRequest for exports, the JDBC2Ident_SyncGroup_JDBCExport and JDBC2Ident_SyncGroup_JDBCExport jobs use their own searchRequest files because they use special anchor values to find the selected attributes. All other JDBC export jobs use the standard searchRequest file.
JDBC Agent Operations
For JDBC agent import:
An LDIF change file is generated by the preceding metacp job:
Dn: consists of: identifying attribute(s), table=tablename
A specific group:
dn:DxrGroupName=verynew,table=Groups
or a specific membership:
dn:MembershipGroupID=1,MembershipAccountID=26,table=Memberships
For JDBC agent export:
An LDIF content file is generated:
A specific group with its memberships:
dn: groupid=1,view=members
groupdesc: xx
groupdxrname: ODBCall
groupid: 1
groupodbcname: all
accountdxrname: bj099999
Add/Delete Membership Lists
Because the JDBC agent cannot currently run in delta mode, the JDBC workflow (JDBC2Ident_SyncGroup_MetaCP job) cannot generate "add" and "delete" member lists. Instead, the workflow accumulates all memberships in the accountDxrName attribute and synchronizes back the complete member list with the common modGroupInRole routine. This operation is different from the ODBC workflow and will be changed when the delta feature is available.
LDAP Provisioning Workflows
The following LDAP workflows to provision any LDAP directory are available:
-
LDAP2_Ident_Validation - performs initial load or validation from an LDAP directory
-
Ident_LDAP_Sync - synchronizes between the Identity Store and an LDAP directory
LDAP Provisioning Workflow Concepts
This chapter defines concepts that are necessary to understand the operation of the LDAP workflows. Per default the workflow assumes groupOfNames at the target system side.
Empty Groups
LDAP groups contain a member or uniqueMember attribute that cannot be empty (it is mandatory and must have a value). This is handled differently on the DirX Identity and the target system side:
-
In the DirX Identity target system the group is empty. Note that the uniqueMember attribute contains the domain name to fulfill the LDAP requirement that empty groups cannot exist (cn=domainName). The dxrGroupMemberOK, dxrGroupMemberAdd and dxrGroupMember attributes are empty.
-
To overcome the problem on the target system side, the LDAP workflow fills empty groups with a customizable value (default is 'cn=no_member'). For configuration of this feature see the next chapter.
LDAP Provisioning Workflow Configuration
This chapter explains how you can customize specific issues of the LDAP workflows.
Empty Groups
Open the User Hooks script of the Identity_LDAP_Sync activity for group synchronization. Adapt the default statement in the Preprocessing section:
set fixGroupMember "cn=no_members"This distinguished name is entered into empty groups on the target system side. If your directory or your applications cannot handle a value that points to nowhere, create an entry in an area that is not synchronized by DirX Identity (to overcome the problem that this entry is synchronized) and set the fixGroupMember value to point to this entry.
Enable / Disable of Accounts
To change the default attribute employeeType to another attribute, perform these steps:
-
Open the User Hooks script for the account activity of the Identity_LDAP_Sync workflow.
-
Select the attribute in the output channel’s Selected Attributes.
-
Edit the statement in the Preprocessing section:
set dxrTSStateAttr "employeeType" -
Open the User Hooks script for the account activity of the Ident2LDAP_Validation workflow.
-
Select the attribute in the input channel’s Selected Attributes.
-
Edit the statement in the Preprocessing section:
set dxrTSStateAttr "employeeType"
LDAP XXL Provisioning Workflows
Group-side storage of memberships in DirX Identity can cause performance problems when large groups (hundred thousands to millions of members) must be handled. One solution is to store the membership at the account instead of at the groups because the number of memberships for accounts typically does not exceed 1000. If the real target system needs group-side membership storage, DirX Identity can nevertheless store the memberships account-side, which significantly improves all internal service handling. DirX Identity’s LDAP XXL workflows support LDAP target systems with this model.
The following LDAP XXL workflows are available:
-
LDAPXXL2_Ident_Validation - performs initial load or validation from an LDAP directory
-
Ident_LDAPXXL_Sync - synchronizes between the Identity Store and an LDAP directory
LDAP XXL General Information
The LDAP XXL workflows operate differently from the standard LDAP workflow, as follows:
-
The validation workflow’s account job reads memberships from the target system and merges them to the identity store accounts. Its group job does not handle memberships.
-
The synchronization workflow’s group job reads memberships from the Identity Store via extra searches and merges them with the groups in the target system. Its account job reads memberships in the target system via extra searches and synchronizes the membership back to the accounts in the Identity Store.
Unlike the standard LDAP workflow, the synchronization workflow’s group job uses the following optimizations:
-
It does not read the member attribute in the LDAP target system into memory (avoids large memory lists)
-
It does not use the Tcl lappend command for large lists (slow function)
-
It does not use the rh arrays (slow Tcl behavior). Instead they build obj modify/create strings
-
It appends/creates members in portions (blocks)
LDAPXXL Workflow Concepts
This section explains LDAPXXL workflow implementation concepts.
New Common Procedures
The two new common procedures are:
-
modGroupStatesInRole
-
addGroupStatesInRole
These procedures handle the states but do not handle the memberships as in the mod/addGroupInRole procedures.
Workflow Integration
Uniquemember is no longer in the target selected attribute list, which prevents it from being read during the join operation.
PostmappingAdd:
The PostmappingAdd: routine:
-
Creates the group via the obj create command. It generates an attribute string for the command from the mapped tgt attributes, and assumes that Abbreviation and Name are identical.
-
Searches the "add" members and appends the first portion of members to the command.
-
Adds all other add members in portions via an obj modify -addattr command.
-
Sets the action to none (because add is already done) and sets a special switch restore_action.
-
Restores the action in loopextraFunction so that backward synchronization of the states can be performed for ADD.
PostmappingMod:
The PostmappingMod: routine:
-
Searches for the members to be deleted.
-
For every member, searches the target system to determine whether or not a delete attribute operation needs to be performed. If it does, the routine builds the list of attributes to be deleted.
-
If a given block size is reached, performs an obj modify -delattr with block_size members.
-
Handles add members analog. Block size is configured at the job (specific attribute block_size defaults to 100).
-
Instead of having a large Tcl (result) list of members, uses the target system as the list. Every search in the list results in an LDAP search.
-
Modifies the other attributes with the standard script operation.
-
Creates a namespace search to handle the searches for add/delete members. It consists of a search and a get(getNextMembers) procedure. The search result is held in this namespace.
-
The get procedure returns the next number of attributes separated by “;”.
LoopExtraFunction
This routine restores the action if the restore_action switch is set.
Additional Statistics
The LDAP XXL workflows offer additional statistics. For example:
#
# Additional statistics:
#==========================
# Nr of groups created: 0
# Nr of modifies to append members for new groups: 0
# Nr of modifies to change memberships: 3
# Nr of groups for which memberships have changed: 1
Specific Attribute block_size (Job)
The job’s block_size attribute is used for creates and modifies. A single create/modify operation handles max block_size members.
Paged-Read Integration
The following sections provide information about paged-read integration in the LDAPXXL workflows.
Group Synchronization
Searches for the add/delete memberships in role may return large results. These searches should use paged read to avoid memory problems. All search functionality is extracted in a Tcl file called “Post Join Search Tcl Script”. It contains three namespaces:
-
A namespace searchType to determine what kind of searches are supported
-
A namespace for simple paging (searchPaged) and
-
A namespace for "simple" searches (search) are provided
| Virtual list view (VLV) may be supported in a future release. |
Simple Paging (paged read)
The searchPaged namespace contains procedures for paged read.
Paged read requires an extra bind with a -bindid option; for users of the search functionality, this is the only difference in the interface between the several search types. As a result, searchPaged offers a bind procedure. The caller passes the bind ID and the connection parameters. The first time bind is called for the given bind ID, it performs the bind. Subsequent calls with the same bind ID do not result in another bind; the existing bind is used.
The page size can be configured at the job object:
variable PAGESIZE <?job@SpecificAttributes(page_size,$default="100")/>Uh:: Prolog:
set st(paged) 0
set rc [searchType::determineSearchType src_bind_id st]
set usePagedResult $st(paged)The variable of uh namespace usePagedResult is set. Here if “simple paging” is possible, usePagedResult is set to 1 (it means true or yes). Otherwise, simple searches are used. If you never want to use simple paging you can hard-code it here.
A second index vlv of the st array indicates whether VLV is supported.
Post-Join Mapping
In postMappingAdd/Mod, the variable usePagedResult is used to determine if search procedures need to be called from search or searchPaged namespace. For usePagedResult, the bind procedure is also called:
if {$usePagedResult == 1} {
set rc [searchPaged::bind paged_bind_id src_conn_param]
}
...
if {$usePagedResult == 0} {
search::SearchMembers $src_conn_param(bind_id) $role_ts_account_base ..
} else {
searchPaged::SearchMembers paged_bind_id $role_ts_account_base ..
}Account Synchronization
The search for the changed accounts in the Identity Store might return a large result. To avoid memory problems, the standard script’s paged read functionality is now used. Paged read is switched on and the page size is set in the account synchronization job’s input channel. Sorting is now disabled (because sorting DDN and paged read is not supported).
Detailed Customization
Perform the following steps to change the Role LDAPXXL workflows from GroupOfUniqueNames to GroupOfNames.
For the validation workflow/validate accounts:
-
Go to the wizard step "Attribute Mapping for Accounts".
-
Edit PostJoin Mapping.
-
In PostJoinMapping Procedure GetCurrentTSMembers, replace
set rc [SearchMembers $bind_id $base_obj GroupOfUniqueNames uniquemember $accountdn locMembs]
with
set rc [SearchMembers $bind_id $base_obj GroupOfNames member $accountdn locMembs]
For the validation workflow/validate groups
-
Wizard step "Attribute Mapping for Groups"
-
Select InputChannel
-
Press show button in Export Properties Tab
-
Update the "Search Filter" of export properties to objectClass="groupOfNames"
For the synchronization workflow/synchronize accounts:
-
In DirX Manager’s expert view: UserHook under the Role_LDAPXXL_SyncAccount_MetaCP job
uh: ModifyRoleEntry procedure:
replace
set rc [SearchMembers $bind_id $base_obj GroupOfUniqueNames uniquemember $accountdn DDN currTSMembs]
with
set rc [SearchMembers $bind_id $base_obj GroupOfNames member $accountdn DDN currTSMembs]
For the synchronization workflow/synchronize groups:
-
Go to the wizard step "Target Selected Attributes for Groups": Replace
uniqueMember replace-all
with
member replace-all -
Go to the wizard step "Import Properties for Groups". In Join Expression,
change GroupOfUniqueNames to GroupOfNames -
Go to the wizard step "Attribute Mapping for Groups": Edit PostJoin Mapping:
postMappingAdd:
Change
set tgt(objectClass) "GroupOfUniqueNames top"
to
set tgt(objectClass) "GroupOfNames top"
Change
set tgt(uniqueMember) $add_member
to
set tgt(member) $add_member
postMappingMod:
Change
set members $found_entry(uniqueMember)
to
set members $found_entry(member)
Change
set tgt(uniqueMember) $members
to
set tgt(member) $members
In the connected directory LDAPXXL:
Configure LDAP TS in Hub:
-
Go to the wizard step "Operational Attributes".
In ObjectClasses Groups, change GroupOfUniqueNames to GroupOfNames
Lotus Notes Provisioning Workflows
This section comprises all Lotus Notes-specific information for Tcl-based workflows.
Tcl-based Lotus Notes Provisioning Workflows
The DirX Identity Tcl-based Lotus Notes workflows provision a Lotus Notes target system. Two workflows are available:
-
Notes2Ident_Validation - performs initial load or validation from a Lotus Notes target system
-
Ident_Notes_Sync - synchronizes between the Identity Store and a Lotus Notes target system
Configuration notes:
-
The parameter "Account Root in TS" of the target system object (in the Provisioning view) must contain a structure element like '/o=mycompany' which must match with the one contained in the cert.id file, because the Notes Server creates the fullname of the user by concatenating givenName, surname and this structure part contained in the cert.id file. This fullname also is used in the member attributes of groups in Notes. As a consequence the cn of a Notes target system account in Provisioning is generated like the fullname in Notes to be able to assign group members to accounts in the Provisioning view.
-
The parameter "Group Root in TS" must be left empty, because groups are kept flat in Notes and not in the kind of structure like users.
Deletion of accounts in Lotus Notes is a specific procedure:
-
The workflow cannot delete accounts directly. Instead it marks an account for deletion in the Lotus Notes system.
-
You can define in the Notes server the time after which an account is physically deleted from the address book (for example, two minutes) and the time after which the mail file is deleted.
-
This feature implies that the dxrTSstate is not set correctly during this run of the synchronization workflow. As a result, the next synchronization workflow will try to delete the same entries again. This action does not result in a warning state. Instead, one of the next synchronization workflows or a validation workflow will set the dxrTS flag accordingly.
UNIX PAM Provisioning Workflows
A Pluggable Authentication Module (PAM) is a method that allows you to provide the authentication for system and other services (login, su, sshd…) using other services (LDAP…). Today the support for PAM is included in most of the common UNIX distributions. PAM was originally developed by Sun Microsystems. The topics in this section describe how PAM works and how to set up PAM Provisioning workflows.
How PAM Works
The basic idea of the PAM system are pluggable authentication modules - shared object files that are typically located in the /lib/security directory. Applications use for access to these modules two interfaces. The first is a system library attached to the application that allows the application to access the application authentication services directly. The second layer is the system configuration - the administrator specifies here the authentication rules for an application as desired.
PAM is used in four areas: user authentication, account control, session management and password change. The PAM modules process control or executive functions:
-
User authentication checks the identity of the user: password check, Kerberos authentication etc.
-
Account control processes some verification which is not directly related to user identity: limited access time for a user, limited number of concurrently logged users etc.
-
Session management is activated before and after service execution: sets the environment variables, execution of chroot, enables network disk connections etc.
-
The control flag describes how to work with the PAM module. The possible values are required, requisite, sufficient and optional.
Setting Up PAM Provisioning Workflows
Provisioning of PAM requires the following setup steps:
-
Install an LDAP directory that you can use for PAM. See the specific vender documentation how to perform this task.
-
Install and configure PAM for your UNIX system. See the specific vendor documentation. This includes a setup of the PAM LDAP schema. Important part of the schema are the object classes posixAccount and posixGroup.
-
Check that PAM is working. Create for example an account and a group that allows access to read a file and check that this account can read the file.
-
Create a UNIX PAM target system in the Provisioning view group with Identity Manager. This includes creation of a UNIX PAM LDAP connected directory and the related workflows.
-
Note: the target system wizard copies only the Tcl-based workflows. If you want to use real-time provisioning, copy the relevant workflows in the Connectivity view group as is described in the DirX Identity Connectivity Administration Guide.
-
Test your scenario thoroughly.
UNIX-PAM Workflows
The UNIX-PAM Provisioning workflows operate between a target system of type LDAP in the Identity Store and the corresponding connected LDAP server that is configured for use with UNIX-PAM (see RFC 2307).
The workflows use the standard LDAP connector (LdapConnector) for provisioning. This connector communicates with the LDAP server across the native LDAP protocol. (See the section "LDAP Workflows" for more information). The following figure illustrates the UNIX-PAM Provisioning workflow architecture.
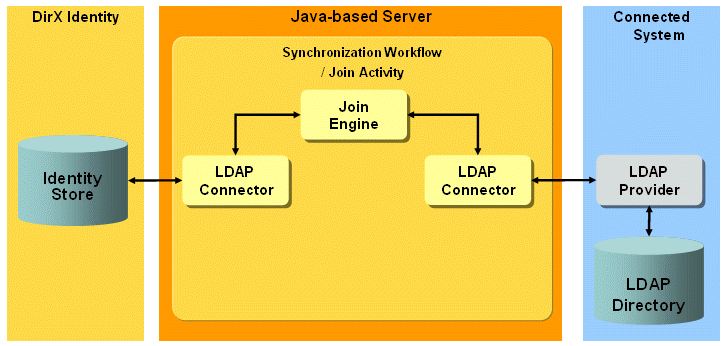
The workflows handle the following UNIX objects:
Account - the common UNIX accounts (object classes posixUser and shadowUser according to RFC 2307).
Group - the common UNIX groups (object classes posixGroup according to RFC 2307).
The delivered workflows are:
-
Ident_UNIX-PAM_Realtime - the synchronization workflow that exports detected changes for account and group objects from Identity Store to the LDAP server and then validates the processed changes in the LDAP server to the Identity Store.
-
Validate_UNIX-PAM_Realtime - the validation workflow that imports existing UNIX accounts and groups with group assignment from the LDAP server to the Identity Store.
UNIX-PAM Workflow Prerequisites and Limitations
The UNIX-PAM workflows have the following prerequisites and limitations:
-
Before you can use the workflows, you must extend the DirX Identity Store schema with UNIX-PAM target system-specific attributes and object classes so that the workflows can store UNIX-PAM-specific information in the Identity Store. For instructions, see the section "Extending the Schema for the Target System Workflows".
-
The workflows support only the object classes posixAccount, shadowAccount and posixGroup defined by RFC 2307.
-
The workflows as delivered do not support password synchronization for UNIX-PAM. (See the section "LDAP Workflows" for an example of a password synchronization workflow for a UNIX-PAM (LDAP-based) connected directory.)
Configuring UNIX-PAM Workflows
To configure the connection to UNIX-PAM:
-
Specify the IP address and the data port of the LDAP server that is configured for use with UNIX-PAM. Use the corresponding UNIX-PAM service object that is the part of the connected UNIX-PAM LDAP directory. Use correct port numbers according to your LDAP server settings. You can also set the usage of secure connection (SSL) or enable client authentication.
-
Set up the bind credentials of the connected LDAP directory representing UNIX-PAM. Use the correct credentials (with sufficient rights). These are the credentials used for administration of the LDAP server. Use the valid DN syntax for the user name.
-
Check the provisioning settings used by the connected UNIX-PAM system. Specify them according to real values for your provisioned UNIX-PAM target system.
Configuring the UNIX-PAM Target System
The UNIX-PAM target system requires the following layout:
-
Accounts - all UNIX accounts are located in a subfolder Accounts.
-
Groups - all UNIX groups are located in a subfolder Groups.
The attribute dxrPrimaryKey of accounts and groups contains the DN of these objects in the connected system.
The standard JavaScript dxrNameForAccounts.js generates the attribute uid for the UNIX account.
The UNIX-PAM specific JavaScript uniqueNumber.js generates the attributes uidNumber and gidNumber for the UNIX account.
The attribute gidNumber for the UNIX account (refers to the primary UNIX group of the account) is by default automatically chosen as one of the assigned UNIX groups. It uses the obligation mechanism (see group objects) and the UNIX-PAM specific JavaScript AccountGidNumber.js. The JavaScript updates the gidNumber when necessary. You can change the primary group manually at the account object.
The group object stores the group membership and references the uid attribute of the account objects.
UNIX-PAM Workflow and Activities
The following figure shows the layout of the channels that are used by the UNIX-PAM workflow’s join activity:
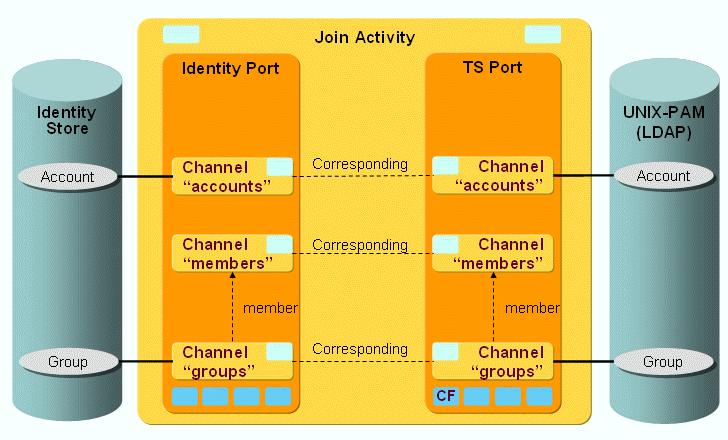
The UNIX objects account and group (and membership) are synchronized via a pair of channels (one channel per direction).
UNIX-PAM Ports
This section describes the UNIX-PAM ports.
TS Port
-
CF - Crypt Filter
A UNIX-PAM filter is implicitly configured. It is used to send the decrypted password attribute userPassword to the LDAP server.
UNIX-PAM Channels
This section provides information about UNIX-PAM channels.
Common Aspects
Direction: Identity Store → UNIX-PAM
-
shadowFlag - the attribute used for disabling of the account object in the connected LDAP directory (used for UNIX-PAM). The correct value is derived from the dxrState attribute of the corresponding account object in the Identity Store. This is an experimental setting and must be supported by the relevant UNIX-PAM implementation.
Direction: UNIX PAM → Identity Store
-
CommonProcsUnixPam.calculateIdInIdentity - calculates the Id.
Accounts
Direction: Identity Store → UNIX-PAM
-
ID: dxrPrimaryKey
-
Join: ${source.dxrPrimaryKey} or ${source.uidNumber}
-
UNIX-PAM requires some mandatory attributes. (See RFC 2307 for details.) Mandatory attributes are mapped in a common way.
-
The gidNumber attribute holds the primary group membership.
Direction: UNIX-PAM → Identity Store
-
Join via the dxrName attribute that is mapped identically to the uidNumber attribute.
Groups
Direction: Identity Store → UNIX-PAM
-
ID: dxrPrimaryKey
-
Join: ${source.dxrPrimaryKey} or {source.gidNumber}
-
UNIX-PAM requires some mandatory attributes. (See RFC 2307 for details.) Mandatory attributes are mapped in a common way.
Direction: UNIX-PAM → Identity Store
-
Join via the dxrName attribute that is mapped identically to the gidNumber attribute.